
1. 지원해야 하는 기능 정리
1.1. 기능적 요구사항
•
파일 업로드/다운로드, 파일 동기화, 알림
•
모바일과 웹 모두 지원
•
파일 크기는 10GB로 제한
•
DAU는 천만이 기준
•
파일 갱신 이력 조회
•
파일 공유
•
파일이 편집되거나 삭제되거나 새롭게 공유되었을 때 알림 표시
1.2. 비기능적 요구사항
•
안정성 : 데이터 손실이 발생하면 안된다.
•
빠른 동기화 속도 : 동기화는 빠르게 진행되어야 사용자에게 신뢰도를 얻을 수 있다.
•
네트워크 대역폭 : 불필요한 네트워크 대역폭을 사용하면 안된다.
•
규모 확장성 : 아주 많은 양의 트래픽도 처리 가능해야 한다.
•
높은 가용성 : 일부 서버가 장애/느려짐/네트워크 오류가 발생해도 계속 작동해야 한다.
1.3. 개략적 추정치
•
모든 사용자에게 10GB의 저장공간 할당
•
각 사용자가 평균 2개의 파일을 업로드 (평균 500KB 가정)
•
읽기:쓰기 비율을 1:1
•
필요 저장공간 총량 = 5천만 X 10GB = 500PB
•
업로드 API QPS = 1천만 X 2회 업로드 / 24h / 3600s = 약 240
•
최대 QPS = QPS X 2 = 480
2. 청사진 그리기
2.1. API
•
API는 총 3가지가 필요하다.
2.1.1. 파일 업로드 API
https://api.example.com/files/upload?uploadType=resumable
•
단순 업로드 : 파일 크기가 작을 때 사용
•
이어 올리기 : 파일 사이즈가 크고 네트워크 문제로 업로드가 중단될 가능성이 높다고 생각되면 사용
◦
이어 올리기 URL을 받기 위한 최초 요청 전송
◦
데이터를 업로드하고 업로드 상태 모니터링
◦
업로드에 장애가 발생하면 장애 발생시점부터 업로드를 재시작
2.1.2. 파일 다운로드 API
https://api.example.com/files/download
•
파일 다운로드 PATH를 인자로 전달하면 다운로드를 시작한다.
2.1.3. 파일 갱신 히스토리 API
https://api.example.com/files/list_revision
•
Path와 limit을 전달해 파일의 히스토리를 확인한다.
2.2. 한대 서버 극복
•
서버가 한대라면 생기는 문제점 = 용량이 다차면 어쩔것이냐
•
가장 간단한 해결 방법은 해시를 사용해 서버를 샤딩하는 것
◦
급한 불은 꺼도 여전히 불안한 구성이다.
◦
장애가 생길 경우 데이터를 잃을 수 있다.

•
S3는 여러 지역에 걸친 다중화를 지원하여 데이터 손실을 막고 가용성을 보장할 수 있다.
•
그럼에도 추후 가용성과 데이터 무결성에 위협을 받을 수 있으므로 대비책을 만들어봤다.
◦
로드밸런서 : 네트워크 트래픽 분산을 위해 사용하고 장애발생 시 스왑을 지원
◦
웹 서버 : 로드밸런서로 인해 손쉽게 추가가능 → 트래픽 대응 쉬움
◦
메타데이터 DB : 파일 저장 서버에서 분리해 SPOF를 회피 → 샤딩 정책을 적용해 가용성과 규모 확장성에 대응
◦
파일 저장소 : S3를 파일 저장소로 사용하고 데이터 무손실을 보장하기 위해 두 개 이상의 지역에 데이터를 다중화
2.3. 동기화 충돌
•
두명 이상의 사용자가 파일을 동시에 수정할 시 충돌이 발생할 수 있다.
•
먼저 수정한 사용자는 성공 이후 수정은 충돌처리한다.
◦
충돌된 파일을 별도로 생성해 파일을 합칠지 아니면 대체할지 결정한다.
2.4. 개략적 설계
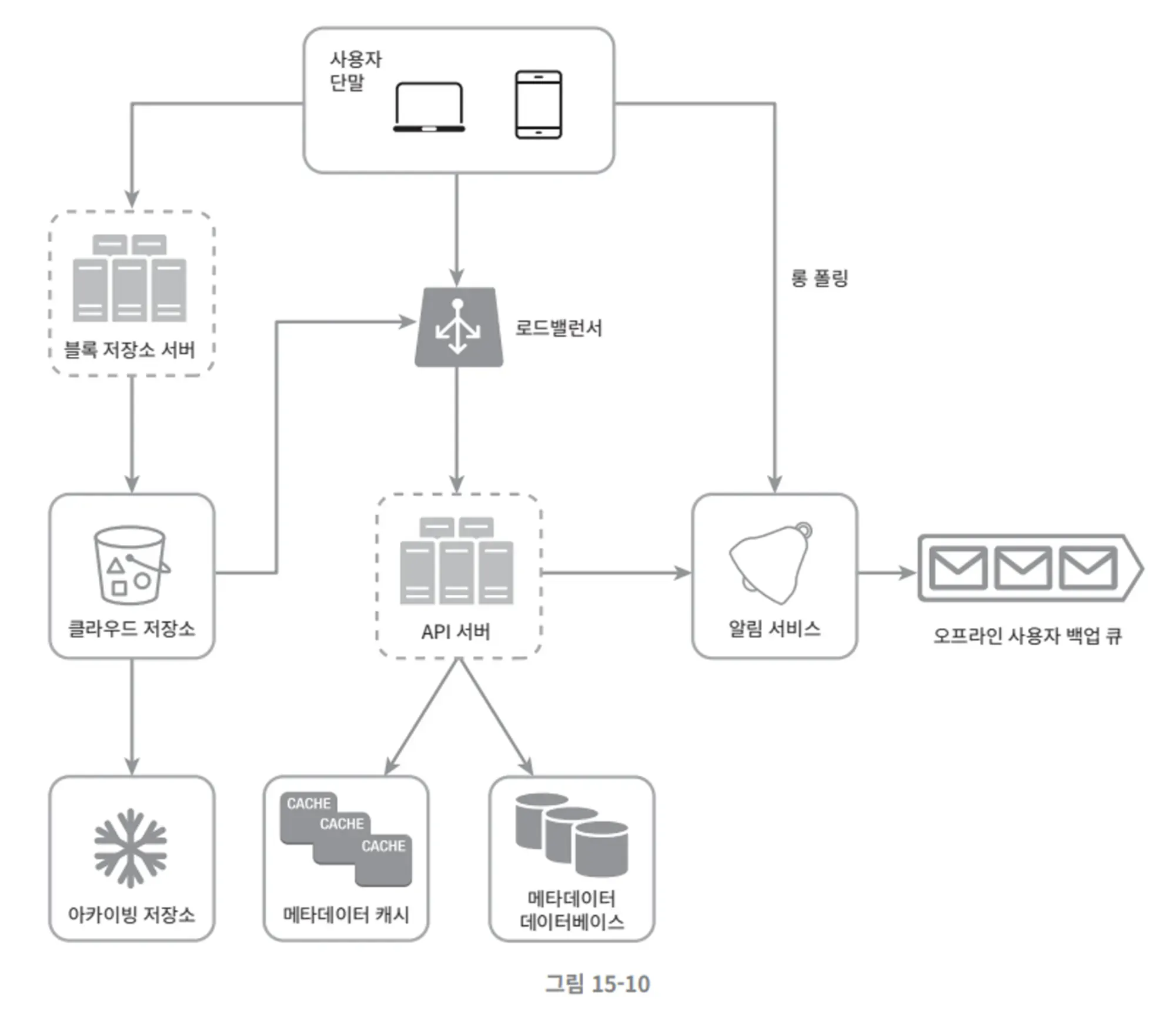
•
블록 저장소 서버
◦
파일 블록을 클라우드 저장소에 업로드하는 서버
◦
블록 저장소는 블록 수준 저장소라고도 불리며 클라우드 환경에서 데이터를 저장하는 기술
•
아카이빙 저장소
◦
오래동안 사용되지 않은 비활성 데이터를 보관하기 위한 시스템
•
메타데이터 데이터베이스
◦
사용자, 파일, 블록, 버전 등의 메타데이터 정보를 관리
•
오프라인 백업 큐
◦
클라이언트가 접속 중이 아니라서 파일의 최신상태를 확인할 수 없을 때 해당 큐를 통해 추후 동기화 될 수 있도록 함
3. 상세설계
3.1. 블록 저장소 서버
•
정기적으로 갱신되는 큰 파일들은 업데이트 시 네트워크 대역폭을 많이 잡아먹는다.
•
최적화 방법은 다음과 같다
1.
델타 동기화 : 파일이 수정되면 전체 파일 대신 수정된 블록만 수정하는 방법이다.
2.
압축 : 블록 단위로 압축해두면 데이터 크기를 줄일 수 있다. 압축 알고리즘은 파일 유형에 따라 정해진다.

•
새 파일이 추가되었을 경우 다음 방식으로 동작
1.
주어진 파일 블록 분할
2.
각 블록 압축
3.
클라우드 저장소로 보내기 전 암호화
4.
클라우드 저장소로 전송
3.2. 높은 일관성 요구사항
•
메모리 캐시는 보통 결과적 일관성 모델을 지원한다.
•
따라서 강한 일관성을 보장하기 위해선 다음 사항을 보장해야 한다.
◦
캐시에 보관된 사본과 데이터베이스의 원본은 일치해야 한다.
◦
원본에 변경이 발생하면 캐시를 무효화 한다.
3.3. 메타데이터 데이터베이스
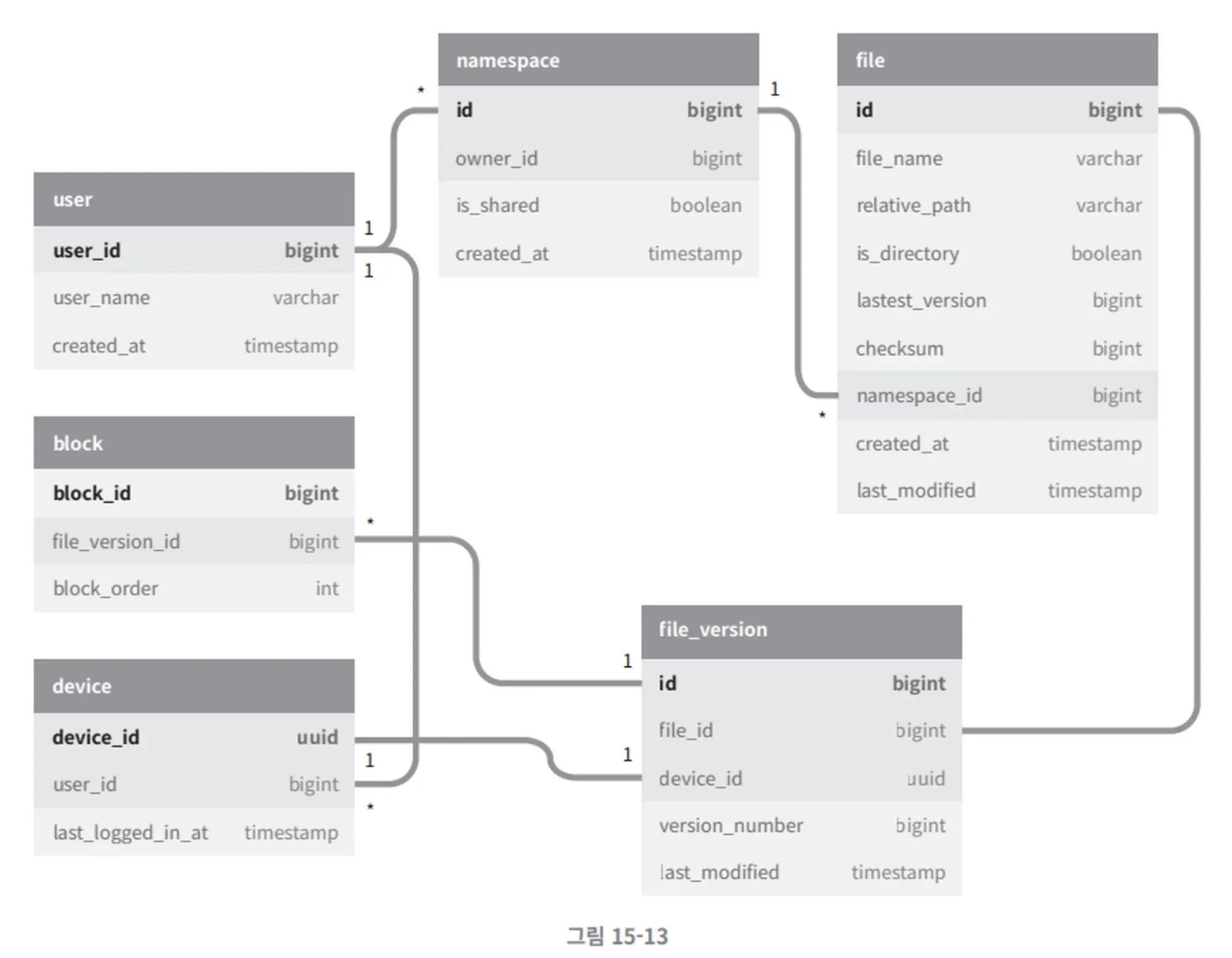
•
스키마 구성도를 참고하자~
3.4. 업로드 절차
•
파일 메타데이터 추가
◦
클라이언트 1이 새 파일의 메타데이터를 추가하기 위한 요청 전송
◦
새 파일의 메타데이터를 데이터베이스에 저장하고 업로드 상태를 대기중으로 변경
◦
새 파일이 추가 됐음을 알림 서비스에 통지
◦
알림 서비스는 관련된 클라이언트에게 파일이 업로드됨을 알림
•
파일을 클라우드 저장소에 업로드
◦
클라이언트 1이 파일을 블록 저장소 서버에 업로드
◦
블록 저장소 서버는 파일을 블록 단위로 쪼갠 다음 압축하고 암호화 한 다음에 클라우드 저장소에 전송
◦
업로드가 끝나면 클라우드 스토리지는 완료 콜백을 호출, 이 콜백 호출은 API 서버로 전송됨
◦
메타데이터 디비에 기록된 해당 파일의 상태를 완료로 변경
◦
알림 서비스에 파일 업로드가 끝남을 통지
◦
알림 발송
3.5. 다운로드 절차
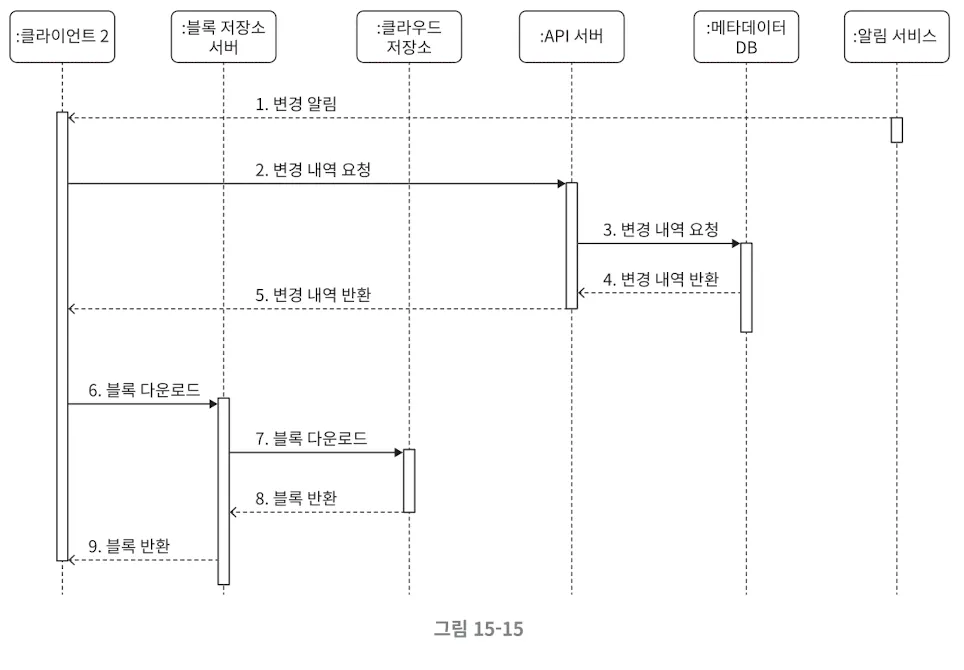
3.6. 알림 서비스
•
일관성 유지를 위해 로컬 파일 수정을 감지하여 알려 충돌 가능성을 줄여야 한다.
•
방법은 다음과 같다
◦
롱 폴링
◦
웹소켓
•
본 서비스는 양방향 통신이 불필요하여 롱폴링을 사용한다.
3.7. 저장소 공간 절약
•
파일 이력 보관은 안정성을 보장하지만 빠르게 저장공간을 소진할 수 있다.
•
이런 문제를 피하기 위한 방법
◦
중복 제거 : 중복된 파일 블록을 계정 차원에서 제거
◦
지능적 백업 전략 도입
▪
자주 바뀌는 파일과 자주 바뀌지 않는 파일을 골라서 보관한다.
▪
보관하는 파일의 개수에 제한을 둔다.
◦
지주 쓰이지 않으면 아카이빙 저장소로 이전한다.
3.8. 장애처리
•
로드밸런서 장애 : 세컨더리 로드밸런서가 활성화해 이어받는다.
•
블록 저장소 서버 장애 : 다른 서버가 미완료 상태/대기상태 작업을 이어받는다.
•
API 서버 장애 : 로드밸런서가 알아서 해준다.
•
클라우드 저장소 장애 : 다른 지역에서 가져온다.
•
메타데이터 캐시 장애 : 다중화 해서 다른 노드에서 가져온다.
•
메타데이터 데이터베이스 장애
◦
주서버 : 부서버를 승격시키고 서버를 새로 추가
◦
부서서 : 다른 서버로 읽기연산 이어받기
•
알림서비스 장애 : 다른서버를 통해 모든 롱 폴링 연결을 복구한다.
•
오프라인 사용자 백업 큐 장애 : 큐를 다중화해 장애시 관계를 재설정한다.
