
개요
RAG(Retrieval-Augmented Generation)는 LLM에게 질의하기 전 외부 지식을 검색해 지식을 제공하는 검색증강생성을 의미한다.
자료가 방대하지 않다면 단순히 프롬프트 만으로도 지식을 제공할 수 있겠지만, 엔터프라이즈 급이라면 말이 좀 달라지게 된다.
너무나도 방대한 자료들이 있고, 이를 제공해주는건 일반적인 DB로는 어려움이 있다.
그렇다면 RAG를 구성하는 방법은 뭐가 있는 것일까?
RAG 기술 파해치기
일반적으로 RAG가 가지는 기술은 VectorDB와 Embedding 모델이 주를 이룬다.
원리로 따지자면 간단한데 각종 정형 및 비정형 데이터를 Embedding 모델을 통해 분석/좌표를 확인한 후 이를 토대로 임베딩 데이터에 인덱스화 시키는 것이다.
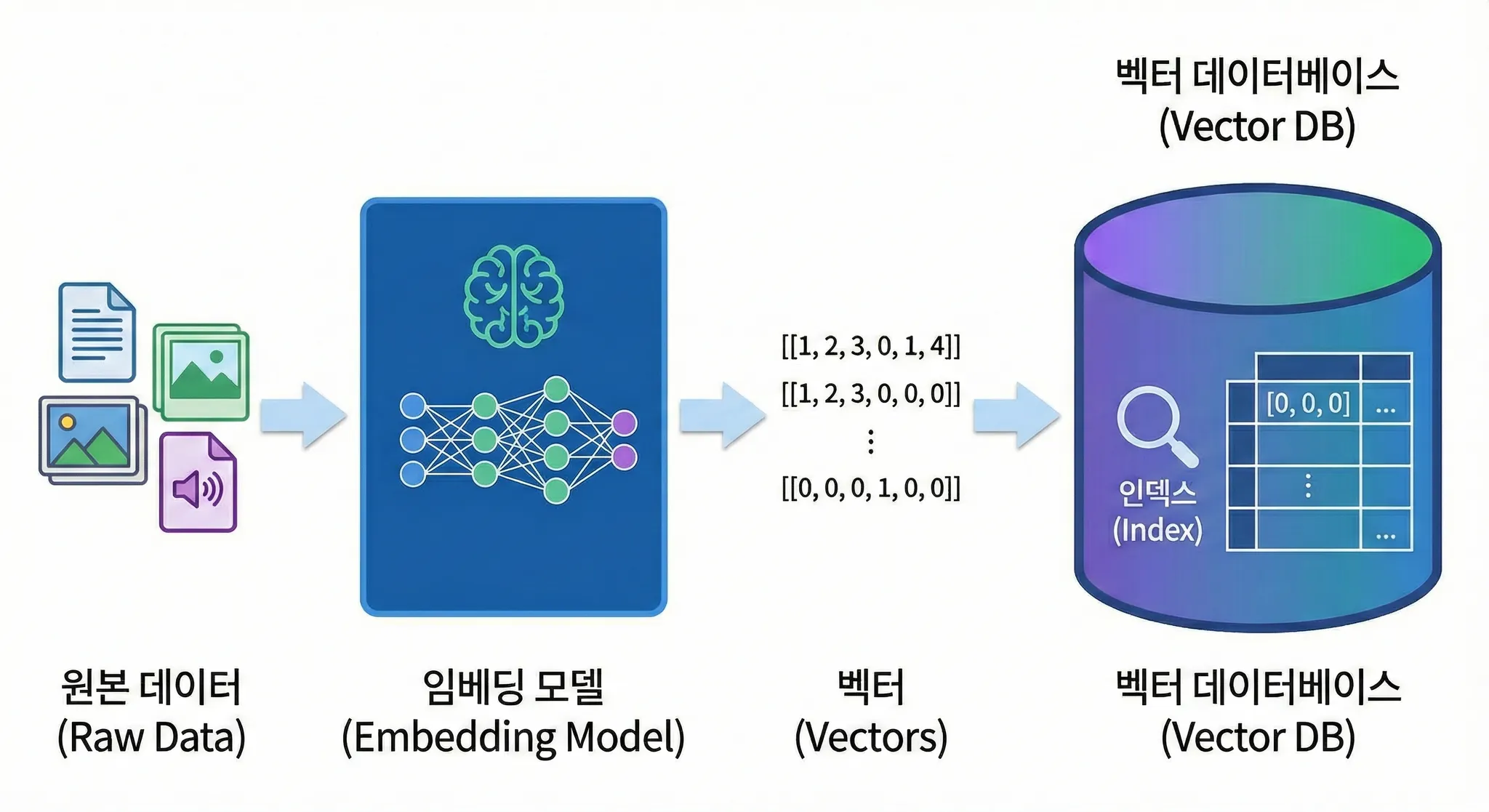
출처 : 나노바나나
이미지에서 설명한 것 처럼 벡터 데이터베이스는 인덱스를 저장해주는 역할을 한다.
그리고 저장된 데이터는 사용자의 기준에 따라 다를 수 있다.
일반적으로 하나의 자료는 너무 크기 때문에 청크 단위로 쪼개어 저장하게 되고, 쪼갠 청크를 임베딩 하여 의미가 있는 데이터로서 활용하게 된다.
Embedding Model
그렇다면 임베딩 모델이라는건 뭘까?
간단히 말하자면 트랜스포머 모델이다.
즉, LLM과 같이 인코더와 디코더를 대규모로 붙여놓은 모델이 아닌 단독적으로 이용하는 트랜스포머라고 보면 된다.
최근엔 이런 임베딩 모델도 장족의 발전을 이뤘기 때문에 보다 다양한 모델들이 등장하고 있는것 같다.
임베딩 모델은 기본적으로 인코더의 구조를 하고 있는데 셀프 어텐션을 통해서 단어와 단어간의 관계를 파악한다.
→ 이를 통해서 “배”라는 단어가 있다면 문장 구조에 따라 이게 타는 배인지 먹는 배인지 파악할 수 있게되었다.
그리고 각 단어들은 고유한 벡터를 가지게 되는데 이를 마지막 히든 레이어에서 Pooling을 통해 하나의 벡터로 생성하게 된다.
Vector
그렇다면 벡터는 뭘까?
벡터는 방향과 크기를 가진 데이터를 의미한다.

그리고 임베딩 모델은 이런 벡터의 차원을 나타낼 수 있는데 사내에서 쓰는 상용 임베딩 모델인 titan embedding v2를 기준으로 출력은 최대 1024까지 지원한다.
이 벡터의 크기가 크면 클 수록 임베딩 모델에서 Pooling을 더 적게 하기 때문의 원문에서 전달한 의미가 더욱 큰 방향성을 가질 수 있게된다.
결과적으로 벡터는 의미(방향)를 가진 문장(크기)를 의미한다.
Vector Store
자 일단 기본 소개의 마지막이다.
벡터 저장소는 앞서 생성한 벡터를 Key-Value 기반으로 저장하고 불러오는 데이터베이스다.
잉? 키 밸류라면 그냥 NoSQL 아닌가? 생각할 수도 있다.
근본으로 따져보자면 그 근간은 NoSQL에서 비롯된게 맞다고 할 수 있지만 목적이 다르다.

출처 : 위키독스 https://wikidocs.net/22384
벡터 저장소는 내적을 통해 이웃한 벡터들을 검색할 수 있도록 도와준다.
어려워 보일 수 있지만 도구를 사용하는 사람으로 아주 상세히 알 필요는 없다고 생각한다.
